 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
DuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
May 20, 2026Recent advances in spoken dialogue language models have shifted from turn-based to full-duplex designs, where the model continuously listens to the user while generating responses. However, existing duplex backbones still lack a native channel for in-conversation planning and tool calling, leaving real-time agentic behaviour either tied to turn boundaries or relegated to an external cascade. We propose DuplexSLA, a native full-duplex Speech-Language-Action foundation model that decodes assistant audio together with a structured action stream on a shared 160 ms chunk timeline. DuplexSLA is built on a dual-stream three-channel formulation: a continuous user audio channel, a discrete assistant audio channel, and a rate-limited textual action channel, all decoded jointly by a single backbone, so that listening, speaking, planning, and tool calling unfold on one shared clock. Two capabilities define the model: (1) semantic-driven turn-taking control, where interruption, pause, and backchannel are handled inside the same backbone instead of by an external semantic VAD; and (2) in-conversation planning and tool calling, where planning text and structured tool calls are emitted on the action channel without halting assistant audio, so that multi-action and backchannel-triggered tool use are interleaved with ongoing speech. To evaluate these capabilities together, we further construct DuplexSLA-Bench, a duplex benchmark covering pause, interrupt, and backchannel turn-taking together with three styles of in-conversation tool calling. Our project page, interactive demos, and the DuplexSLA-Bench evaluation suite are publicly available at https://github.com/hyzhang24/DuplexSLA.
Boosting Omni-Modal Language Models: Staged Post-Training with Visually Debiased Evaluation
May 13, 2026Omni-modal language models are intended to jointly understand audio, visual inputs, and language, but benchmark gains can be inflated when visual evidence alone is enough to answer a query. We study whether current omni-modal benchmarks separate visual shortcuts from genuine audio-visual-language evidence integration, and how post-training behaves under a visually debiased evaluation setting. We audit nine omni-modal benchmarks with visual-only probing, remove visually solvable queries, and retain full subsets when filtering is undefined or would make comparisons unstable. This yields OmniClean, a cleaned evaluation view with 8,551 retained queries from 16,968 audited queries. On OmniClean, we evaluate OmniBoost, a three-stage post-training recipe based on Qwen2.5-Omni-3B: mixed bi-modal SFT, mixed-modality RLVR, and SFT on self-distilled data. Balanced bi-modal SFT gives limited and uneven gains, RLVR provides the first broad improvement, and self-distillation reshapes the benchmark profile. After SFT on self-distilled data, the 3B model reaches performance comparable to, and in aggregate slightly above, Qwen3-Omni-30B-A3B-Instruct without using a stronger omni-modal teacher. These results show that omni-modal progress is easier to interpret when evaluation controls visual leakage, and that small omni-modal models can benefit from staged post-training with self-distilled omni-query supervision. Project page: https://cheliu-computation.github.io/omni/
Step-Audio-R1.5 Technical Report
Apr 28, 2026Recent advancements in large audio language models have extended Chain-of-Thought (CoT) reasoning into the auditory domain, enabling models to tackle increasingly complex acoustic and spoken tasks. To elicit and sustain these extended reasoning chains, the prevailing paradigm -- driven by the success of text-based reasoning models -- overwhelmingly relies on Reinforcement Learning with Verified Rewards (RLVR). However, as models are strictly optimized to distill rich, continuous auditory contexts into isolated, verifiable text labels, a fundamental question arises: are we fostering true audio intelligence, or merely reducing a continuous sensory medium into a discrete puzzle? We identify this as the "verifiable reward trap." While RLVR yields remarkable scores on standardized objective benchmarks, it systematically degrades the real-world conversational feel of audio models. By prioritizing isolated correctness over acoustic nuance, RLVR reduces dynamic interactions to mechanical "answering machines," severely compromising prosodic naturalness, emotional continuity, and user immersion, particularly in long-turn dialogues. To bridge the gap between mechanical objective verification and genuine sensory empathy, we introduce Step-Audio-R1.5, marking a paradigm shift toward Reinforcement Learning from Human Feedback (RLHF) in audio reasoning. Comprehensive evaluations demonstrate that Step-Audio-R1.5 not only maintains robust analytical reasoning but profoundly transforms the interactive experience, redefining the boundaries of deeply immersive long-turn spoken dialogue.
Learning Evidence Highlighting for Frozen LLMs
Apr 24, 2026Large Language Models (LLMs) can reason well, yet often miss decisive evidence when it is buried in long, noisy contexts. We introduce HiLight, an Evidence Emphasis framework that decouples evidence selection from reasoning for frozen LLM solvers. HiLight avoids compressing or rewriting the input, which can discard or distort evidence, by training a lightweight Emphasis Actor to insert minimal highlight tags around pivotal spans in the unaltered context. A frozen Solver then performs downstream reasoning on the emphasized input. We cast highlighting as a weakly supervised decision-making problem and optimize the Actor with reinforcement learning using only the Solver's task reward, requiring no evidence labels and no access to or modification of the Solver. Across sequential recommendation and long-context question answering, HiLight consistently improves performance over strong prompt-based and automated prompt-optimization baselines. The learned emphasis policy transfers zero-shot to both smaller and larger unseen Solver families, including an API-based Solver, suggesting that the Actor captures genuine, reusable evidence structure rather than overfitting to a single backbone.
Generative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
Step-Audio-EditX Technical Report
Nov 05, 2025


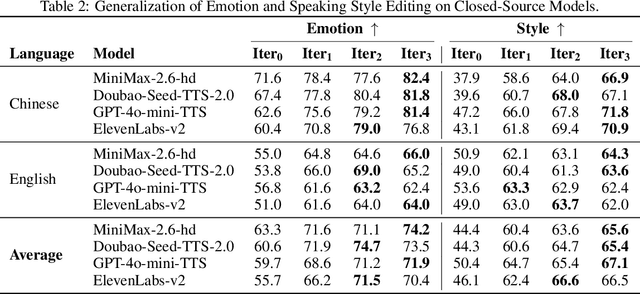
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.